Book
Submodule 14.2: DOM methods/properties and DOM Recursion
Submodule 14.2: DOM methods/properties and DOM Recursion
Completion requirements
View
Recursion
Recursion, in simple words, is a function which calls itself.
The theoretical concept of recursion is complex and you can learn more about it on the JavaScript tutorial: Recursion page.
It is generally used when the same method is needed multiple times in order to get the output that you want.
For example, if we want to walk across the entire DOM and do something with each node, we actually need to do the same thing multiple times. In this case, recursion is a great way to achieve what we want. Let's see that in practice.
If we had the html code :
<!DOCTYPE html><html>
<head></head>
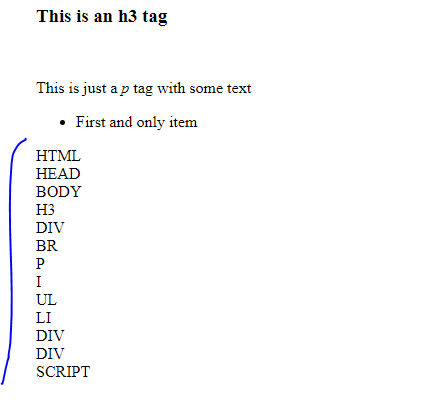
<body> <h3>This is an h3 tag</h3> <div id="divTag"></div> <br /> <p id="pTag">This is just a <i>p</i> tag with some text</p> <ul> <li> First and only item </li> </ul> <div> <div id="output"></div> </div></body>
</html> We can use the concept of recursion to traverse the document and output all the names of the Nodes. The code to achieve this is: <script> window.onload = function () {
var outEl = document.getElementById("output"); var str = ''; function traverse(el) {
str += el.nodeName + "<br>";
for (var i = 0; i < el.children.length; i++) { traverse(el.children[i]); }
}
traverse(document.documentElement); outEl.innerHTML = str;
} </script> In the above code, the traverse function calls itself inside the for loop. If we didn't use recursion here and just had a for loop, the output would have been only the first node element ( HTML). The result of the above code will be :